Confluent Schema Registry provides a centralized repository for an organization’s schemas and a version history of the schemas as they evolve over time. The first format supported by Schema Registry was Avro. Avro was developed with schema evolution in mind, and its specification clearly states the rules for backward compatibility, where a schema used to read an Avro record may be different from the schema used to write it.
In addition to Avro, today Schema Registry supports both Protobuf and JSON Schema. JSON Schema does not explicitly define compatibility rules, so in this article I will explain some nuances of how compatibility works for JSON Schema.
Grammar-Based and Rule-Based Schema Languages
In general, schema languages can be either grammar-based or rule-based.1 Grammar-based languages are used to specify the structure of a document instance. Both Avro and Protobuf are grammar-based schema languages. Rule-based languages typically specify a set of boolean constraints that the document must satisfy.
JSON Schema combines aspects of both a grammar-based language and a rule-based one. Its rule-based nature can be seen by its use of conjunction (allOf), disjunction (oneOf), negation (not), and conditional logic (if/then/else). The elements of these boolean operators tend to be grammar-based constraints, such as constraining the type of a property.
Open and Closed Content Models
A JSON Schema can be represented as a JSON object or a boolean. In the case of a boolean, the value true will match any valid JSON document, whereas the value false will match no documents. The value true is a synonym for {}, which is a JSON schema (represented as an empty JSON object) with no constraints. Likewise, the value false is a synonym for { "not": {} }.
By default, a JSON schema provides an open content model. For example, the following JSON schema constrains the properties “foo” and “bar” to be of type “string”, but allows any additional properties of arbitrary type.
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" }
}
}
The above schema would accept the following JSON document, containing a property named “zap” that does not appear in the schema:
{
"foo": "hello",
"bar": "world",
"zap": 123
}
In order to specify a closed content model, in which additional properties such as “zap” would not be accepted, the schema can be specified with “additionalProperties” as false.
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" }
},
"additionalProperties": false
}
Backward, Forward, and Full Compatibility
In terms of schema evolution, there are three types of compatibility2:
- Backward compatibility – all documents that conform to the previous version of the schema are also valid according to the new version
- Forward compatibility – all documents that conform to the new version are also valid according to the previous version of the schema
- Full compatibility – the previous version of the schema and the new version are both backward compatible and forward compatible
For the schemas above, Schema 1 is backward compatible with Schema 2, which implies that Schema 2 is forward compatible with Schema 1. This is because any document that conforms to Schema 2 will also conform to Schema 1. Since the default value of “additionalProperties” is true, Schema 1 is equivalent to
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" }
},
"additionalProperties": true
}
Note that the schema true is backward compatible with false. In fact
- The schema
true(or{}) is backward compatible with all schemas. - The only schema backward compatible with
trueistrue. - The schema
false(or{ "not": {} }) is forward compatible with all schemas. - The only schema forward compatible with
falseisfalse.
Partially Open Content Models
You may want to allow additional unspecified properties, but only of a specific type. In these scenarios, you can use a partially open content model. One way to specify a partially open content model is to specify a schema other than true or false for “additionalProperties”.
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" }
},
"additionalProperties": { "type": "string" }
}
The above schema would accept a document containing a string value for “zap”:
{
"foo": "hello",
"bar": "world",
"zap": "champ"
}
but not a document containing an integer value for “zap”:
{
"foo": "hello",
"bar": "world",
"zap": 123
}
Later one could explicitly specify “zap” as a property with type “string”:
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" },
"zap": { "type": "string" }
},
"additionalProperties": { "type": "string" }
}
Schema 5 is backward compatible with Schema 4.
One could even accept other types for “zap”, using a oneOf for example.
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" },
"zap": {
"oneOf": [ { "type": "string" }, { "type": "integer" } ]
}
},
"additionalProperties": { "type": "string" }
}
Schema 6 is also backward compatible with Schema 4.
Another type of partially open content model is one that constrains the additional properties with a regular expression for matching the property name, using a patternProperties construct.
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" }
},
patternProperties": {
"^s_": { "type": "string" }
},
"additionalProperties": false
}
The above schema allows any other properties other than “foo” and “bar” to appear, as long as the property name starts with “s_” and the type is “string”.
Understanding Full Compatibility
When evolving a schema in a backward compatible manner, it’s easy to add properties to a closed content model, or to remove properties from an open content model. In general, there are two rules to follow to evolve a schema in a backward compatible manner:
- When adding a property in a backward compatible manner, the schema of the property being added must be backward compatible with the schema of “additionalProperties” in the previous version of the schema.
- When removing a property in a backward compatible manner, the schema of “additionalProperties” in the new version of the schema must be backward compatible with the schema of the property being removed.
The rules for forward compatibility are similar.
- When adding a property in a forward compatible manner, the schema of the property being added must be forward compatible with the schema of “additionalProperties” in the previous version of the schema.
- When removing a property in a forward compatible manner, the schema of “additionalProperties” in the new version of the schema must be forward compatible with the schema of the property being removed.
For example, to add a property to an open content model, such as Schema 3, in a backward compatible manner, one can add it with type true, since true is the only schema that is backward compatible with true, as previously mentioned.
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" },
"zap": true
}
"additionalProperties": true
}
The property “zap” has been added, but it’s been specified with type true, which means that it can match any valid JSON. Schema 3 and Schema 8 are also fully compatible, since they both accept the same set of documents.
This leads to a way to evolve a closed content model, such as Schema 2, in a fully compatible manner, by adding a property of type false.
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" },
"zap": false
}
"additionalProperties": false
}
Admittedly, Schema 9 is not very interesting, because in this case the property “zap” matches nothing.
The rules for full compatibility can now be stated as follows.
- When adding a property in a fully compatible manner, the schema of the property being added must be fully compatible with the schema of “additionalProperties” in the previous version of the schema.
- When removing a property in a fully compatible manner, the schema of “additionalProperties” in the new version of the schema must be fully compatible with the schema of the property being removed.
Using Partially Open Content Models for Full Compatibility
The previous examples of full compatibility are of limited use, since they only allow new properties to match anything using true, in the case of an open content model, or to match nothing using false, in the case of a closed content model. To achieve full compatibility in a meaningful manner, one can use a partially open content model, such as Schema 4, which I repeat below.
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" }
},
"additionalProperties": { "type": "string" }
}
Schema 4 allows one to add and remove properties of type “string” in a fully compatible manner. What if you want to add properties of either type “string” or “integer”? You could specify additionalProperties with a oneOf, as in the following schema:
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" }
},
"additionalProperties": {
"oneOf": [ { "type": "string" }, { "type": "integer" } ]
}
}
But with the above schema, every fully compatible schema that adds a new property would have to specify the type of the property as a oneOf as well:
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" },
"zap": {
"oneOf": [ { "type": "string" }, { "type": "integer" } ]
}
},
"additionalProperties": {
"oneOf": [ { "type": "string" }, { "type": "integer" } ]
}
}
An alternative would be to use patternProperties. The rules in the previous section regarding adding and removing properties do not apply when using patternProperties.
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" }
},
"patternProperties": {
"^s_": { "type": "string" },
"^i_": { "type": "integer" }
},
"additionalProperties": false
}
With Schema 12, one can add properties of type “string” that start with “s_”, or properties of type “integer” that start with “i_”, in a fully compatible manner, as shown below with “s_zap” and “i_zap”.
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "string" },
"s_zap": { "type": "string" },
"i_zap": { "type": "integer" }
},
patternProperties": {
"^s_": { "type": "string" },
"^i_": { "type": "integer" }
},
"additionalProperties": false
}
Achieving full compatibility in a meaningful way is possible, but requires some up-front planning, possibly with the use of patternProperties.
Summary
JSON Schema is unique when compared to other schema languages like Avro and Protobuf in that it has aspects of both a rule-based language and a grammar-based language. A better understanding of open, closed, and partially-open content models can help you when evolving schemas in a backward, forward, or fully compatible manner.












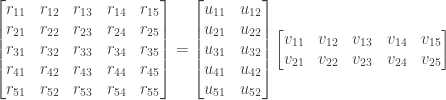
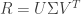
 is a diagonal matrix of weights. The values in the row or column for the user-feature matrix or item-feature matrix are referred to as latent factors. The exact meanings of the latent factors are usually not discernible. For a movie, one latent factor might represent a specific genre, such as comedy or science-fiction; while for a user, one latent factor might represent gender while another might represent age group. The goal of Funk SVD is to extract these latent factors in order to predict the values of the user-item rating matrix.
is a diagonal matrix of weights. The values in the row or column for the user-feature matrix or item-feature matrix are referred to as latent factors. The exact meanings of the latent factors are usually not discernible. For a movie, one latent factor might represent a specific genre, such as comedy or science-fiction; while for a user, one latent factor might represent gender while another might represent age group. The goal of Funk SVD is to extract these latent factors in order to predict the values of the user-item rating matrix.

