In previous posts, I had discussed how Kafka can be used for both stream-relational processing as well as graph processing. I will now show how Kafka can also be used to process Datalog programs.
The Datalog Language
Datalog 1 is a declarative logic programming language that is used as the query language for databases such as Datomic and LogicBlox.2 Both relational queries and graph-based queries can be expressed in Datalog, so in one sense it can be seen as a unifying or foundational database language. 3
Finite Model Theory
To mathematicians, both graphs and relations can be viewed as finite models. Finite model theory has been described as “the backbone of database theory”4. When SQL was developed, first-order logic was used as its foundation since it was seen as sufficient for expressing any database query that might ever be needed. Later theoreticians working in finite model theory were better able to understand the limits on the expressivity of first-order logic.
For example, Datalog was shown to be able to express queries involving transitive closure, which cannot be expressed in first-order logic nor in relational algebra, since relational algebra is equivalent to first-order logic.5 This led to the addition of the WITH RECURSIVE clause to SQL-99 in order to support transitive closure queries against relational databases.
Facts and Rules
Below is an example Datalog program.
parent(’Isabella’, ’Ella’). parent(’Ella’, ’Ben’). parent(’Daniel’, ’Ben’). sibling(X, Y) :- parent(X, Z), parent(Y, Z), X̸ != Y.
The Datalog program above consists of 3 facts and 1 rule.6 A rule has a head and a body (separated by the :- symbol). The body is itself a conjunction of subgoals (separated by commas). The symbols X, Y, and Z are variables, while ‘Isabella’, ‘Ella’, ‘Ben’, and ‘Daniel’ are constants.
In the above program, the facts state that Isabella has a parent named Ella, Ella has a parent named Ben, and Daniel has a parent named Ben. The rule states that if there exist two people (X and Y) who are not the same (X != Y) and who have the same parent (Z), then they are siblings. Thus we can see that Ella and Daniel are siblings.
The initial facts of a Datalog program are often referred to as the extensional database (EDB), while the remaining rules define the intensional database (IDB). When evaluating a Datalog program, we use the extensional database as input to the rules in order to output the intensional database.
Datalog Evaluation
There are several ways to evaluate a Datalog program. One of the more straightforward algorithms is called semi-naive evaluation. In semi-naive evaluation, we use the most recently generated facts (

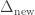

Semi-naive evaluation is essentially how incremental view maintenance is performed in relational databases.
So how might we use Kafka to evaluate Datalog programs? Well, it turns out that researchers have shown how to perform distributed semi-naive evaluation of Datalog programs on Pregel, Google’s framework for large-scale graph processing. Since Kafka Graphs supports Pregel, we can use Kafka Graphs to evaluate Datalog programs as well.
Datalog on Pregel
The general approach for implementing distributed semi-naive evaluation on Pregel is to treat each constant in the facts, such as ‘Ella’ and ‘Daniel’, as a vertex in a complete graph.8 The value of each vertex will be the complete set of rules 
Beyond the straightforward approach described above9, many enhancements can be made, such as efficient grouping of vertices into super-vertices, rule rewriting, and support for recursive aggregates.10
Datalog Processing With Kafka Streams
Based on existing research, we can adapt the above approach to Kafka Graphs, which I call KDatalog.11
Assuming our Datalog program is in a file named siblings.txt, we first use KDatalog to parse the program and construct a graph consisting of vertices for the constants in the program, with edges between every pair of vertices. As mentioned, the initial value of the vertex for a given constant 
StreamsBuilder builder = new StreamsBuilder();
Properties producerConfig = ...
FileReader reader = new FileReader("siblings.txt");
KGraph<String, String, String> graph =
KDatalog.createGraph(builder, producerConfig, reader);
We can then use this graph with KDatalog’s implementation of distributed semi-naive evaluation on Pregel, which is called DatalogComputation. After the computation terminates, the output of the algorithm will be the union of the values at every vertex.
Since KDatalog uses Kafka Graphs, and Kafka Graphs is built with Kafka Streams, we are essentially using Kafka Streams as a distributed Datalog engine.
The Future of Datalog
Datalog has recently enjoyed somewhat of a resurgence, as it has found successful application in a wide variety of areas, including data integration, information extraction, networking, program analysis, security, and cloud computing.12 Datalog has even been used to express conflict-free replicated data types (CRDTs) in distributed systems. If interest in Datalog continues to grow, perhaps Kafka will play an important role in helping enterprises use Datalog for their business needs.
- The name “Datalog” was coined by David Maier while working with David Warren on the book Computing With Logic, 1988.
- Databases that use Datalog as a query language are often referred to as deductive databases. LogicBlox actually supports a superset of Datalog that is called LogiQL.
- Relational algebra is equivalent in expressive power to Datalog where rules are restricted to be safe, nonrecursive, and have only stratified negation.
- Victor Vianu. Databases and Finite Model Theory. 1997.
- This is known as Codd’s theorem.
- Both facts and rules are together referred to as Horn clauses.
- The result is referred to as the least fixed point of the program. In finite model theory, Datalog with negation has shown to be equivalent to existential least fixed point logic.
- A complete graph is a graph in which each pair of graph vertices is connected by an edge.
- Matthias Maiterth. Parallel Datalog on Pregel. 2012.
- Walaa Eldin Moustafa, et. al. Datalography: Scaling Datalog Graph Analytics on Graph Processing Systems. 2016
- KDatalog is essentially of a port of the Parallel Datalog on Pregel work, which uses Apache Giraph. Many Pregel algorithms can easily be translated from Apache Giraph to Kafka Graphs.
- Shan Shan Huang, et. al. Datalog and Emerging Applications: An Interactive Tutorial. 2011.